Tracking Communities in Social Networks
Blogging is not rocket science it's about being yourself and putting what you have into it.. and when it's about Complex Networks then definitely I remember Albert Einstein's statement "Any fool can make things bigger, more complex and more violent. It takes a touch of genius and a lot of courage to move in the opposite direction.."
A social network is usually modeled as a graph in which vertices represent entities
and edges represent interactions between pairs of entities.Previously,a
community was often defined to be a subset of vertices that are densely connected
internally but sparsely connected to the rest of the network. Accordingly, the best
community of the graph was typically a peripheral set of vertices barely connected to
the rest of the network by a small number of edges. However, as per the new view that for
large-scale real-world societies, communities, though better connected internally than
expected solely by chance, may also be well connected to the rest of the network.It is hard to imagine a small close-knit community with only a few edges connecting
it to the outside world.

As shown the Computer Science community may be well attached to other parts of the network as well.
With this intuitive notion of community, two types of structures are defined:
the “whiskers” and the “core”. Whiskers are peripheral subsets of vertices that are
barely connected to the rest of the network, while the core is the central piece that
exclusively contains the type of community we are interested in. Then, the algorithm
for finding a community can be reduced to two steps:
- identifying the core in which no whiskers exist
- identifying communities in the core.
In this way, one
can obtain communities that are not only more densely connected than expected by
chance alone, but also well connected to the rest of the network.
Much of the early work on finding communities in social networks focused on partitioning
the corresponding graph into disjoint sub components. Algorithms
often required dense graphs and conductance was widely taken as the measure of the
quality of a community. Given a graph G = (V, E), the conductance of a
subset of vertices S ⊆ V is defined as:


where the 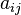 are the entries of the adjacency matrix for G and a(S) is the total number (or weight) of the edges incident with S. A subset
was considered to be community-like when it had low conductance value. However, as
discussed earlier, an individual may belong to multiple communities at the same time
and will likely have more connections to individuals outside of his/her community
than inside. One approach to finding such well-defined overlapping communities is the concept of an (α, β)-community and
several algorithms were given for finding an (α, β)-community in a dense graph under
certain conditions. Given a graph G = (V, E) with self-loops added to all vertices, a
subset C ⊆ V is called an (α, β)-community when each vertex in C is connected to
at least β vertices of C (self-loop counted) and each vertex outside of C is connected
to at most α vertices of C (α < β).
are the entries of the adjacency matrix for G and a(S) is the total number (or weight) of the edges incident with S. A subset
was considered to be community-like when it had low conductance value. However, as
discussed earlier, an individual may belong to multiple communities at the same time
and will likely have more connections to individuals outside of his/her community
than inside. One approach to finding such well-defined overlapping communities is the concept of an (α, β)-community and
several algorithms were given for finding an (α, β)-community in a dense graph under
certain conditions. Given a graph G = (V, E) with self-loops added to all vertices, a
subset C ⊆ V is called an (α, β)-community when each vertex in C is connected to
at least β vertices of C (self-loop counted) and each vertex outside of C is connected
to at most α vertices of C (α < β).
are the entries of the adjacency matrix for G and a(S) is the total number (or weight) of the edges incident with S. A subset
was considered to be community-like when it had low conductance value. However, as
discussed earlier, an individual may belong to multiple communities at the same time
and will likely have more connections to individuals outside of his/her community
than inside. One approach to finding such well-defined overlapping communities is the concept of an (α, β)-community and
several algorithms were given for finding an (α, β)-community in a dense graph under
certain conditions. Given a graph G = (V, E) with self-loops added to all vertices, a
subset C ⊆ V is called an (α, β)-community when each vertex in C is connected to
at least β vertices of C (self-loop counted) and each vertex outside of C is connected
to at most α vertices of C (α < β).
Among the interesting questions being explored are why (α, β)-communities correspond
to well-defined clusters and why there is no sequence of intermediate (α, β)-
communities connecting one cluster to another. Other intriguing questions include
whether different types of social networks incorporate fundamentally different social
structures; what it is about the structure of real-world social networks that leads to
the structure of cores, as in the Twitter graph, and why some synthetic networks do
not display this structure.
By taking the intersection of a group of massively overlapping (α, β)-communities
obtained from repeated experiments, one can eliminate random factors and extract
the underlying structure. In social graphs, for large community size k, the (α, β)-
communities are well clustered into a small number of disjoint cores, and there are
no isolated (α, β)-communities scattered between these densely-clustered cores. The
number of cores decreases as k increases and becomes relatively small for large k. The
cores obtained for a smaller k either disappear or merge into the cores obtained for
a larger k. Moreover, the cores correspond to dense regions of the graph and there
are no bridges of intermediate (α, β)-communities connecting one core to another.
In contrast, the cores found in several random graph models usually have significant
overlap among them, and the number of cores does not necessarily decrease as k
increases. Extensive experiments demonstrate that the core structure displayed in
various large-scale social graphs is, indeed, due to the underlying social structure
of the networks, rather than due to high-degree vertices or to a particular degree
distribution.
RESOLUTION LIMIT : A popular method for community identification now widely used relies on the optimization of a quantity called modularity, which is a quality index for a partition of a network into communities. If one chooses modularity as the relevant quality function, the problem of community detection becomes equivalent to modularity optimization. The latter is not trivial, as the number of possible partitions of a network into clusters increases at least exponentially with the size of the network, making exhaustive optimization computationally unfeasible even for relatively small graphs. Therefore, a number of algorithms have been devised to find a good optimization technique with the smallest computational cost possible.
It is impossible to tell whether a module (large or small), detected through modularity optimization, is indeed a single module or a cluster of smaller modules. This raises doubts about the effectiveness of modularity optimization in community detection, and more generally about the applicability of quality functions.
So I guess it's time to wind up. Resolution Limit shall be covered in the next blog.Hope you all liked it.Waiting for your responses.
REFERENCES :
- http://www.pnas.org/content/104/1/36.full
- http://www.jstor.org/stable/30035025?seq=1#page_scan_tab_contents This is an excellent paper on meeting strangers and friends of friends.
- http://www.cs.cornell.edu/~lwang/wang11ijsi.pdf
No comments:
Post a Comment